![[WIL]머신러닝 - 2주차 강의 개발일지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FUeKej%2FbtrqmpVkJRE%2FFG1VKKduOuYy6KYHEyZZZ0%2Fimg.png)
2주 차의 목표는 논리 회귀의 개념과 다양한 머신러닝 모델을 알아본다.
머신러닝에서 쓰이는 전처리 기법들에 대해 배운다.
논리 회귀 : 입력값과 결과 사이에 연관성을 찾아내는 것을 말함
전처리 : 로우 데이터의 값에서 오류나 잘못된 점을 걸러내는 기법, 또는 분석하기 쉽게 먼저 가공해놓는 방법
1. 논리 회귀 (Logistic regression)
1주 차에는 선형 회귀에 대하여 알아보는 시간이 있었는데 이 선형 회귀는 연속된 값으로 선의 형태로 나타내는 방법이었다. 하지만 논리 회귀는 단어에서도 나타내어져 있듯이 해당 값은 시험의 합격, 불합격 또는 일의 성공과 실패와 같은 결과값이 연속된 것이 아닌 특정한 결과값을 가르치는 형태이기에 연속된 입력값에 의해서 동등하게 정비례 또는 반비례하여 결과값을 나타내는 것과는 다른 모습을 나타내게 된다.

강의에서는 선형 회귀에서 가설로 사용된 위와 같은 그래프의 모습을 우스꽝스럽다고 표현하였는데 이 의미는 당연히 논리 회귀에서의 결과 값은 0~1을 벗어나게 된다면 의미가 없지만 위 그래프는 그 값을 벗어나는 형태를 띠고 있기 때문이다.
이런 그래프를 논리 회귀에 맞는 모양으로 변경시켜주기 위하여 사용하는 것이 Sigmoid 함수이다.

시그모이드 함수(Sigmoid function)를 사용하게 되면 결과값은 0~1 사이로 제한되게 되며 자연적으로 일어나는 현상에서는 위와 같은 S자 커브 형태를 따르는 모델이 많다.
여기서 중요한 것은 "이런 그래프를 논리 회귀에 맞는 모양으로 변경시켜주기 위하여 사용하는 것이 Sigmoid 함수이다."
논리 회귀에서 손실 함수는 시그마 i는 1부터 m까지 일 때로 시작하는 어려운 수식이지만 한번 일고 외우지는 않았다 개념만 알고 갈 수 있도록 하자
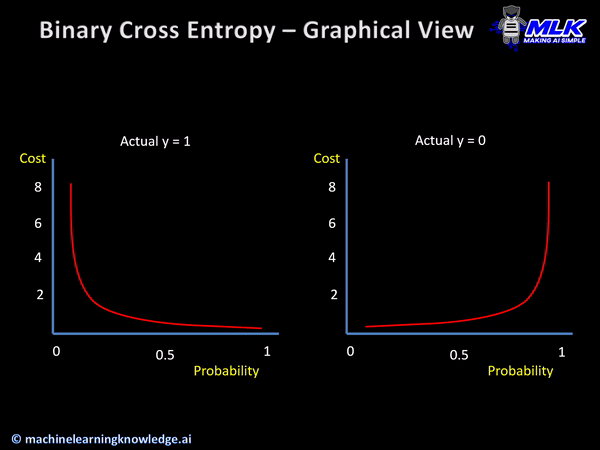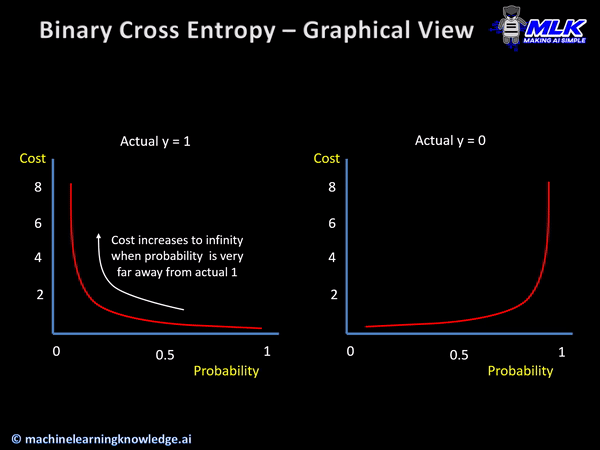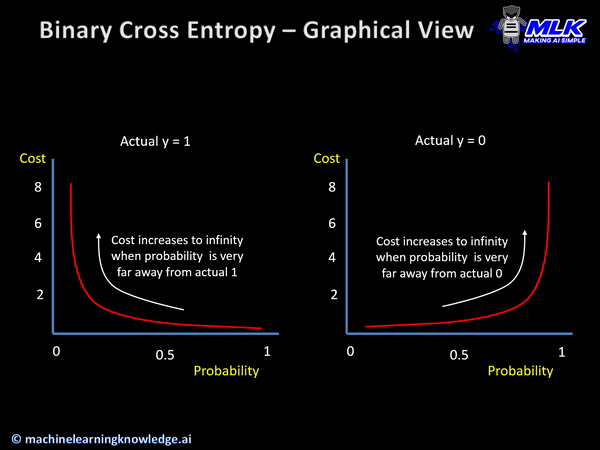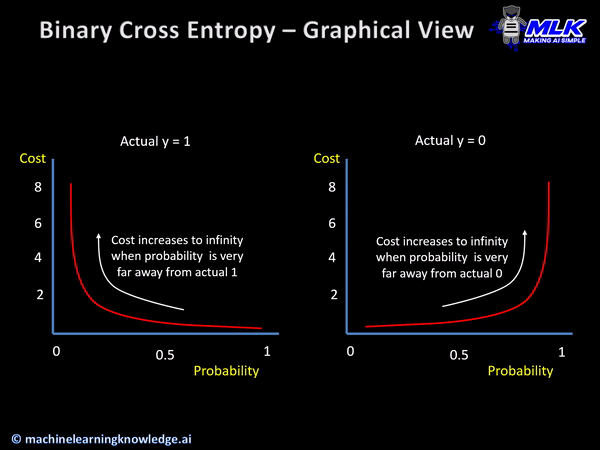
아주 간단하게 생각하면 된다 제대로 이해하려면 아주 복잡하겠지만 말이다. 위의 표는 간단하게 구현해 내야 하는 값이라고 생각하면 되겠다. 어떤 입력값이 들어가도 위와 같은 확률 분포표가 나오면 되는 것이다. 위 사진의 왼쪽 그래프로 설명을 해보면 Actual y라고 표시한 값이 참의 값이기 때문에 확률이 높다고 표시할수록 실제 결과와 가까워지기에 Cost는 점점 줄어들고 반대로 확률이 낮다고 표현할수록 실제 값에 도달할 수 없기에 Cost가 높다고 표현된다.
이런 그래프의 모습을 최종 출력 모습이라고 생각할 때 어떠한 입력값을 위와 같은 출력 값으로 만들어주는 함수를 Crossentropy라고 한다. 현재 배우고 있는 Keras에서는 이진 논리 회귀의 경우에 binary_crossentropy 손실 함수를 사용한다.
2. 다항 논리 회귀 (Logistic regression)
다항 논리 회귀도 위와 같은 논리 회귀의 한 종류로써 그 결과값을 2개로만 나타내는 것이 아니고 어떤 값의 범위에 따라 여러 가지 결과값으로 나누어 놓은 방법을 말한다.
원핫 인코딩 ( one-hot encoding )
해당 회귀 방법의 출력 값을 인지하기 쉽게 만들 수 있는 방법 중에 하나는 원핫 인코딩이다. 이 작업을 거치게 되면 0,1로 구성된 이진 배열의 모습으로 결과값을 나타낼 수 있다.
원핫 인코딩을 만드는 방법은 라벨의 개수( 여기서 라벨은 결괏값의 종류 )대로 배열을 구성, 각 클래스의 인덱스 위치 선정, 각 클래스의 인덱스 위치에 1을 기입하는 방식으로 수행된다.
Softmax function
Softmax는 선형 모델에서 나온 모든 결과를 합치면 1이 되도록 해주는 함수이다.
이렇게 하는 이유는 어떤 입력값에 대한 결과값이 모든 경우에 따라 나오게 구성되어있다고 한다면 그 라벨의 합은 1이 될 수밖에 없기 때문에 이렇게 확률로 표현하기 위하여 sofrmax function을 사용한다.
Keras에서 다항 논리 회귀의 경우에는 categorical_crossentropy 손실 함수를 사용한다.
3. 다양한 머신러닝 모델
Support vector machine (SVM)
특징에 따른 분류 상태에서 가상의 선을 그어줘서 그 선과의 거리를 통하여 분류하여 학습하는 방법으로 예외가 발생하였을 때 다른 특징을 추가해가면서 구분할 수 있다.
k-Nearest neighbors (KNN)
특징에 따라서 분류 문제를 풀 때 어떤 개체의 주변에 있는 개체들을 군집시켜 구분하는 알고리즘이다.
Decision tree (의사결정 나무)
스무고개 형식으로 예, 아니오로 된 문항을 반복하며 추론하는 방식
*아키네이터가 바로 생각이 났었다.
4. 머신러닝에서 전처리
전처리는 데이터의 정제 작업이며 위에서 잠깐 설명한 것과 같이 필요 없는 데이터를 지우는 것부터, 정규화를 하고, 표준화를 하는 것을 나타낸다.
1. 필요 없는 데이터를 지우는 행위는 정말 일반적인 값에서 많이 떨어지는 예외를 삭제시켜주는 것을 뜻한다.
2. 정규화는 값의 최댓값과 최소값을 0~1 사이의 숫자로 변환해주는 것을 말한다.
3. 표준화는 데이터의 분포를 정규분포로 바꿔주며 평균이 0 표준편차가 1로 만들어 주는 것을 말한다.
밑의 사진은 표준화의 의미를 나타내어 준다.
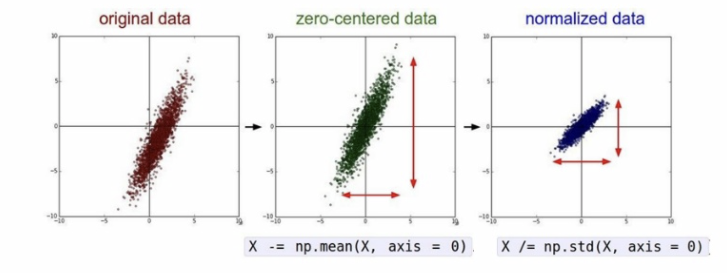
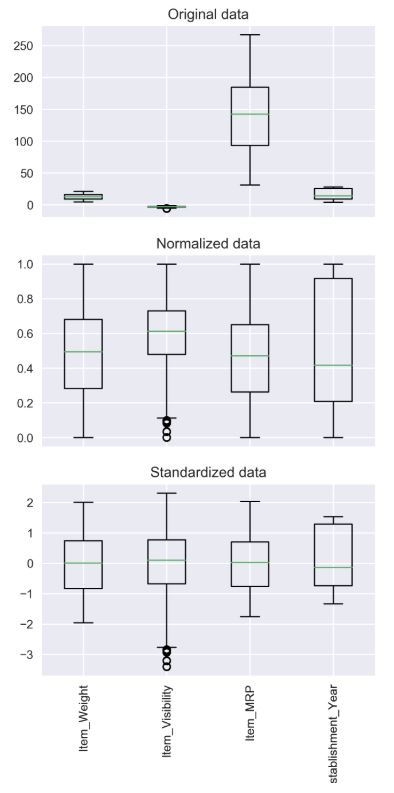
2주 차 강의 요약
논리 회귀는 입력값과 결과 사이에 연관성을 찾아내는 것을 말하며 전처리는 말 그대로 이렇게 연관성을 찾아내기 전에 데이터를 미리 가공하여 연관성을 더욱 빠르고 정확하게 찾아낼 수 있도록 하는 과정을 말한다.
논리 회귀를 크게 두 가지로 나눠보자면 이진 논리 회귀와 다항 논리 회귀가 있고 논리 회귀라는 특성상 결괏값이 0과 1로 수렴하여야 하기에 sigmoid함수를 쓰게 되며 이진 논리 회귀의 경우에는 keras binary_crossentropy를 사용한다.
다항 논리회로에서는 원할 인코딩, Softmax 함수를 사용하며 keras에서는 categorical_crossentropy를 사용한다.
머신러닝에는 다양한 종류가 있고 Support vector machine (SVM), k-Nearest neighbors (KNN), Decision tree (의사결정 나무) 대하여 학습했다.
머신러닝에서는 전처리 과정을 거쳐야 하며 여기서 거치는 과정은 필요 없는 데이터를 sorting 해내고 정규화, 표준화하는 과정을 거친다.
'DevLog' 카테고리의 다른 글
| [WIL]머신러닝 - 4주차 강의 개발일지 (0) | 2022.01.11 |
|---|---|
| [WIL]머신러닝 - 3주차 강의 개발일지 (0) | 2022.01.11 |
| [WIL]머신러닝 - 1주차 강의 개발일지 (0) | 2022.01.10 |
| [WIL]내일배움캠프 AI트랙 1기 3주차 주간회고 (0) | 2022.01.04 |
| [Setting]Robo 3T 설정하기 - MongoDB Database (0) | 2021.12.28 |