![[WIL]머신러닝 - 1주차 강의 개발일지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FCaxKY%2FbtrqnjGSY9K%2Fy43avsT8xbSoDKKPoow16k%2Fimg.png)
머신러닝의 기원을 생각해본다면 사람들이 예측하고 싶은 여러가지 이벤트를 사람이 모두 고려하기에는 어려움이 있기에 컴퓨터가 직접 그런 예측에 필요한 인자들을 학습하고 예측할 수 있게 하기 위하여 발전하게 되었다.
그리고 우리가 자주 접하는 단어인 딥러닝은 머신러닝의 방법 중 하나이다.
머신러닝이 발전하는 초기에는 이 딥러닝을 MLP(Multi-Layer Perceptron)이라고 불렸으나 어감이 좋은 딥러닝으로 정착화 되었다.
1. 해답을 찾는 방식
머신러닝으로 문제를 풀때 해답을 찾는 방식은 크게 회귀 or 분류로 나눌 수 있다.
회귀는 출력값을 연속적인 소수점으로 예측하게 하도록 푸는 방법을 이야기 하고 분류는 정해진 출력값에 따라서 분류하는 것을 분류라고 한다.
* 하지만 이렇게 연속적인 값이라는 것도 어떻게 보면 사람이 정해놓은 무한한 숫자안에 의미를 부여하여 하나하나 분류를 하는 것인데 어떻게 보면 출력값이 엄청나게 많은 다중분류와 회귀가 같은 내용이고 이름만 다르게 부르는 것이 아닌지 생각을 하였다.
2. 학습의 종류
지도( Supervised learning ) : 정답을 알려주면서 학습 시키는 방법
정답 값이 있을때 정답값을 알려주면 학습 시키는 방법
정답 값이 없을때 정답을 하나씩 입력해주는 작업을 하게 되는데 이것을
라벨링(Labeling, 레이블링) 또는 어노테이션(Annotation) 이라고 한다.
비지도( Unsupervised learning ) : 정답을 알려주지 않고 군집화(Clustering) 하는 방법
정답이 없기때문에 데이터의 특성을 분류하는 것을 목적으로 한다. 이러한 데이터의 특성을 분류하여 그룹핑을 하는데
군집 (Clustering), 시각화(Visualization)와 차원 축소(Dimensionality Reduction), 연관 규칙 학습(Association Rule Learning)의 방법등 방법이 여러가지이다.
강화 ( Reinforcement learning ) : 주어진 데이터 없이 실행과 오류를 반복하면서 학습하는 방법
말그대로 주어진 데이터가 없이 행동을 하고 그 행동을 기반으로 보상을 점수로 만들어서 저장하고 수많은 시행착오를 거치면서 더욱 높은 보상을 얻을 수 있는 방식으로 행동의 방향을 결정하게 만드는 방법이다.
개념에서는 이것을
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
으로 설명하였으며 영어단어로는 의미가 이상해 보이는 것이 있어 이것을 나의 해석으로 풀어서 이야기 하자면 에이전트(Agent)는 행위의 주체가 환경(Environment) 어떤 게임이나 행동의 틀 안에서 상태(State) 각각의 조건에 따라서 행동(Action) 행하는 행동을 보상(Reward) 점수로 정하여 이것을 데이터로 축적하여 더 높은 점수의 방향으로 행동하게 만드는 것이다.
이것은 과거에는 실생활에 적용할 수 있을 만큼 좋은 결과를 낼 수 있는 학습 모델이 아니었지만 학습에 신경망을 적용하면서부터 바둑이나 자율주행차와 같은 복잡한 문제에 적용할 수 있게 되었다고 한다.
* 학습기법중에 아주 유망한 기법으로 생각됨
3. 선형 회귀 (Linear Regression)
위에 회귀를 설명했던것과 같이 선형으로 이루어진 회귀 우리 주변에 일어나는 무수히 많은 불규칙한 현상을 선형으로 설명할 수 있다는 것에 착안하여 나타내본다고 생각하면 됨
선형회귀에서 중요한 개념은 가설과 손실함수
가설 : 자신이만든 임의의 직선
손실함수 : 가설과 실제의 거리 Cost라고도 한다.
추가 개념
다중 선형 회귀(Multi-variable linear regression) : 선형 회귀와 똑같지만 입력 변수가 여러개인 선형회귀
4. 경사 하강법 (Gradient descent method)
예측 모델을 만들때 중요한것은 세운 가설에서의 손실함수를 최소화(Optimize) 하는 것이다.
컴퓨터는 사람처럼 수식을 풀 수 없으므로 경사 하강법이라는 방법을 써서 점진적으로 문제를 풀어갈 수 밖에 없다.
여기서 중요한 개념은 lr이며 향후 코드에서 필히 작성해주어야 하는 부분이다.
이것을 풀어쓰면 Learning rate 말그대로 배우는 비율이고 한번에 얼마씩 전진하는지의 단위라고 생각하면 되겠다.
이렇게 전진하면서 손실함수가 최소화 되는 부분에 도달하게 되면 학습을 종료하게 된다.
Learning rate가 작을때는 손실함수가 최소화 되는 부분에 도달하는 시간이 오래걸릴 가능성이 크고 Learning rate 클때는 찾으려는 값을 지나치고 값을 못찾고 최소화 되는 부분 근처에서 값이 진동하다가 최악의 경우에는 값이 무한대로 발산 할 수 있다. 이렇게 발산하는 상황을 Overshooting이라고 한다.
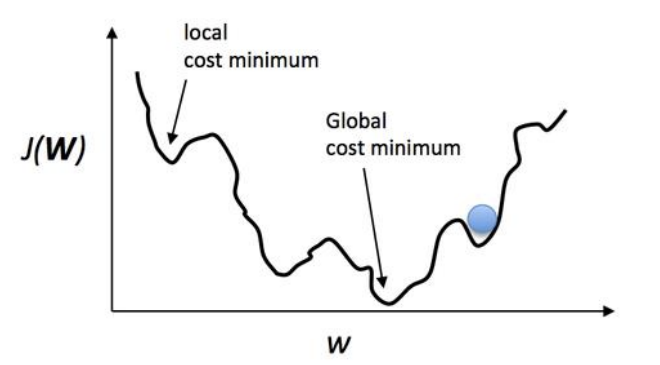
그리고 이 Learning rate의 설정이 중요한 이유중 하나는 우리가 탐색하게 되는 손실함수의 모습이 언제나 완만한 또는 일정하게 줄어들고 늘어나는 곡선의 모습을 이루지는 않기 때문에 Learning rate의 값을 잘못 설정하게 되면 위의 사진에 보여지는 Local cost minimum에 빠질 가능성이 많아지기에 특별히 조심하고 검증하는 과정을 거칠 수 있도록 하여야한다.
5. 데이터셋 분할
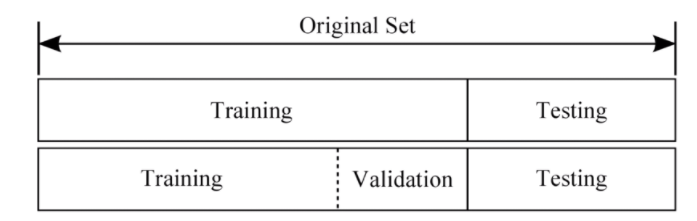
데이터 셋 분할에서는 아주 간단하게 3가지만 생각하면 된다.
Training set : 머신러닝 모델 학습시키는 용도로 사용 전체의 약 80%의 비중
Validation set : 모델을 검증하는 용도로 사용 전체의 약 20%의 비중
Test set : 정답 라벨이 없는 실제 환경에서의 데이터셋
3가지를 나누는 것은 학습과 이 학습 내용을 분석하기 위한 툴이라고 생각하면 되겠다.
아무리 잘 학습이 된 학습모델이라고 할지라도 그 정확성을 수치화 시켜서 나타낼수 있지 않다면 실제로 사용할 수 없는 데이터가 될 뿐이기에 전체 데이터셋을 일정 비율 나누어 주는 작업을 하고 학습을 시키고 그 수치를 확인하는 곳에 사용하게 된다.
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)위의 코드는 간략하게 데이터 셋을 Training set과 Validation set으로 나누는 것을 나타낸 코드다.
1주차 강의 요약
실생활에서 일어나는 여러가지 방대한 데이터에 따른 결과를 예측하기 위하여 머신러닝이 시작되었고 방식은 회귀와 분류로 나누어 볼 수 있겠다. 학습의 종류에는 지도, 비지도, 강화 학습법이 있다.
이중 선형회귀는 결과를 예측할때 가설이라는 예측값을 만드는데 이때 가설의 정확도를 나타내는 지표인 손실함수를 줄이기위하여 Leaning rate를 잘 설정한 경사하강법을 사용하여야 하며 이렇게 데이터를 이용하여 컴퓨터를 학습 시킬때는 데이터셋을 분할하여, 학습에 이용하는 데이터와 이것이 유효한지 검사할때 사용하는 데이터를 분류하여 주어야한다.
'DevLog' 카테고리의 다른 글
| [WIL]머신러닝 - 3주차 강의 개발일지 (0) | 2022.01.11 |
|---|---|
| [WIL]머신러닝 - 2주차 강의 개발일지 (0) | 2022.01.11 |
| [WIL]내일배움캠프 AI트랙 1기 3주차 주간회고 (0) | 2022.01.04 |
| [Setting]Robo 3T 설정하기 - MongoDB Database (0) | 2021.12.28 |
| [WIL]내일배움캠프 AI트랙 1기 2주차 주간회고 (0) | 2021.12.26 |