![[백준_1260] DFS와 BFS](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fq97Yw%2FbtrBaygtOqS%2FCAF0oap4kfheBnI6e80WRk%2Fimg.gif)
문제 보기: https://www.acmicpc.net/problem/1260
1260번: DFS와 BFS
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사
www.acmicpc.net
문제
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
새로 사용된 개념
1. 깊이 우선 탐색 (DFS, Depth-First Search)
: 최대한 깊이 내려간 뒤, 더이상 깊이 갈 곳이 없을 경우 옆으로 이동
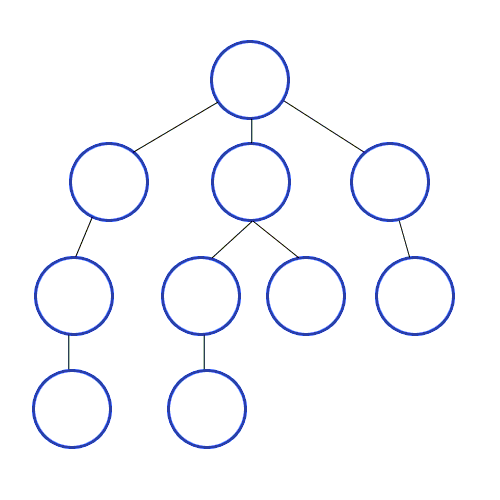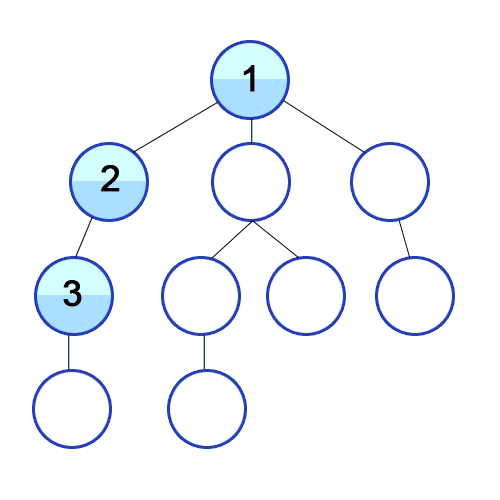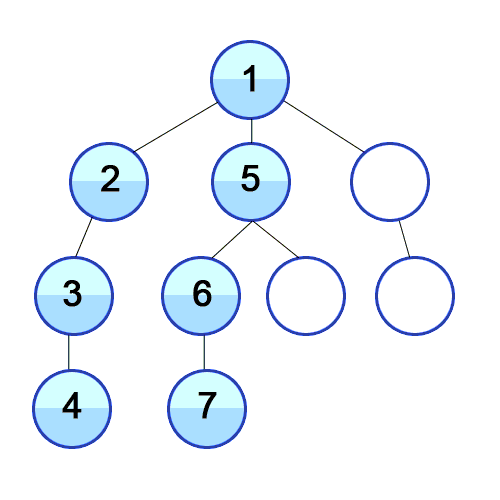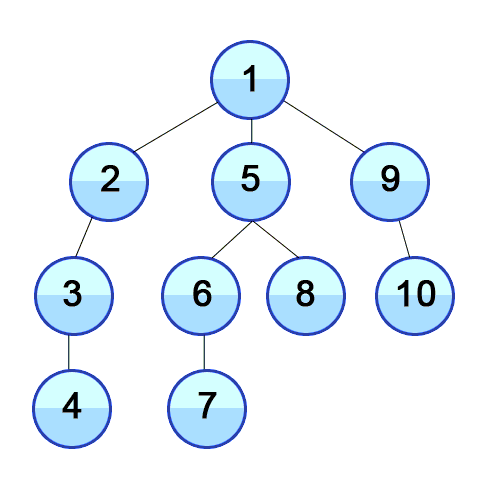
💡 깊이 우선 탐색의 개념
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에
해당 분기를 완벽하게 탐색하는 방식을 말합니다.
예를 들어, 미로찾기를 할 때 최대한 한 방향으로 갈 수 있을 때까지 쭉 가다가
더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길로 돌아와서
그 갈림길부터 다시 다른 방향으로 탐색을 진행하는 것이 깊이 우선 탐색 방식이라고 할 수 있습니다.
1. 모든 노드를 방문하고자 하는 경우에 이 방법을 선택함
2. 깊이 우선 탐색(DFS)이 너비 우선 탐색(BFS)보다 좀 더 간단함
3. 검색 속도 자체는 너비 우선 탐색(BFS)에 비해서 느림
2. 너비 우선 탐색 (BFS, Breadth-First Search)
: 최대한 넓게 이동한 다음, 더 이상 갈 수 없을 때 아래로 이동
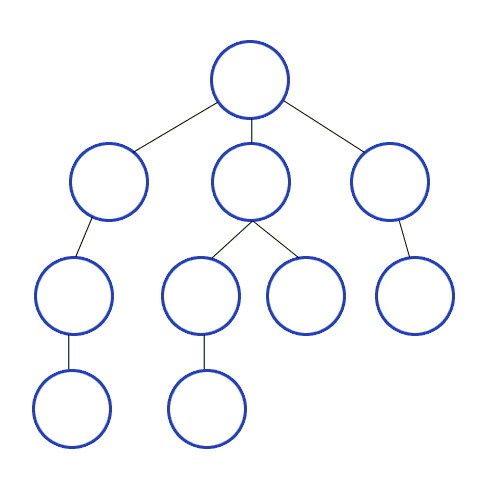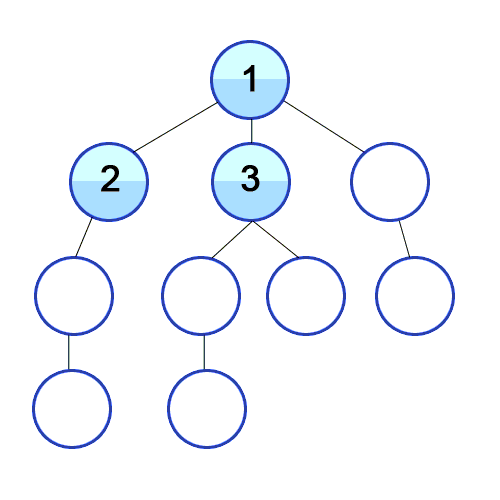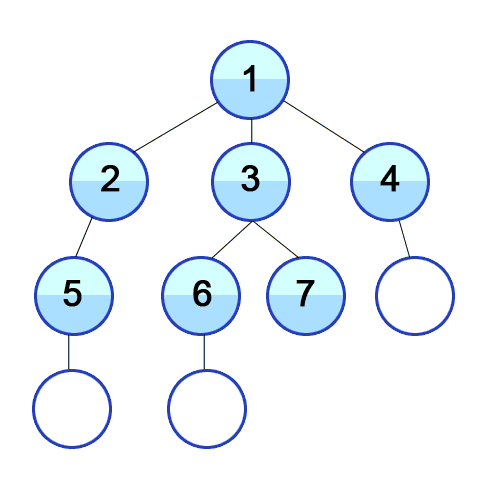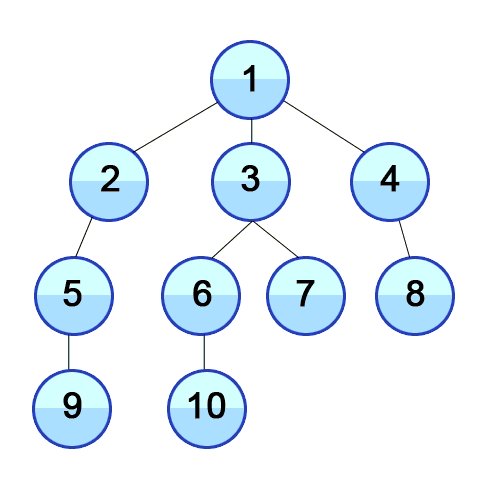
💡 너비 우선 탐색의 개념
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법으로,
시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법입니다.
주로 두 노드 사이의 최단 경로를 찾고 싶을 때 이 방법을 선택합니다.
ex) 지구 상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Sam과 Eddie사이에 존재하는 경로를 찾는 경우
* 깊이 우선 탐색의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모름
* 너비 우선 탐색의 경우 - Sam과 가까운 관계부터 탐색
출처 : https://devuna.tistory.com/32
[알고리즘] 깊이 우선 탐색(DFS) 과 너비 우선 탐색(BFS)
[알고리즘] 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS) 그래프를 탐색하는 방법에는 크게 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)이 있습니다. 📌여기서 그래프란, 정점(node)과 그 정점을 연
devuna.tistory.com
새로운 함수
print(*dfslist)
print(*bfslist)리스트를 출력할때 *을 사용하여 대괄호를 제외하고 출력할 수 있다.
풀이 과정
1. dfs와 bfs는 따로 변수를 구성하여 작업을 하도록 한다.
2. 정점의 갯수대로 visit 정보를 나타낼수 있는 리스트를 준비한다.
3. bfs와 dfs 함수를 따로 구성하는데 그 방법은 밑의 설명과 같다.
4. bfs에서는 큐의 형태라고 생각하면서 방문했는지 여부를 확인해서 append
5. dfs는 재귀함수를 이용하여 한쪽 끝까지 탐색하면서 값을 얻어낸다.
코드
import sys
n, m, v = map(int, sys.stdin.readline().split())
lines = [[0 for _ in range(n + 1)] for __ in range(n + 1)]
for _ in range(m):
a, b = map(int, sys.stdin.readline().split())
lines[a][b] = lines[b][a] = 1
dfsvisited = [0 for _ in range(n + 1)]
bfsvisited = [0 for _ in range(n + 1)]
dfslist = []
bfslist = []
def dfs(x):
dfsvisited[x] = 1
dfslist.append(x)
for i in range(1, n + 1):
if dfsvisited[i] == 0 and lines[x][i] == 1:
dfs(i)
def bfs(x):
q = [x]
bfsvisited[x] = 1
while q:
x = q.pop(0)
bfslist.append(x)
for i in range(1, n + 1):
if bfsvisited[i] == 0 and lines[x][i] == 1:
q.append(i)
bfsvisited[i] = 1
dfs(v)
bfs(v)
print(*dfslist)
print(*bfslist)
'Algorithm' 카테고리의 다른 글
| [백준_2108] 통계학 (0) | 2022.05.07 |
|---|---|
| [백준_18258] 큐 2 (0) | 2022.05.06 |
| [백준_1874] 스택 수열 (0) | 2022.05.05 |
| [백준_4949] 균형잡힌 세상 (0) | 2022.05.04 |
| [백준_1010] 다리 놓기 (0) | 2022.05.03 |